コミックマーケット103 声優イラスト本表紙
COTA
生き方のチュートリアル – COTA


AIは可愛くないから駄目です。個性ある失敗をしない、失敗したら今度は認めずに堂々とシラを切る、八方ブス(八方美人)であらゆる人に「かもしれません」などといい顔をして、信念もない、未熟なのに純情さがない、表層だけで人間の垢を煮詰めた、知識こそあるけど知識だけで生きて薄っぺらい、人に依存しないと存在できないのに人間面しながら自分という核も持たないグロテスクな存在です。2024年時点では。
さてそんな人工知能・生成AIについては便利な一方で実在する・実在した人物を元に本人の意思に反する動画を生成させて政治的な利用をされたり、実在しない名所が生成され観光サイトに載せ閉鎖する問題があったり、あるいは他人のイラストレーターの作品を許諾を得ずに生成させたイラストを商用に利用することなどが2024年・最近の問題点としてよく挙げられます。
そんな中、2024年12月現在では生成AIがGoogleの検索でも結果の中に要約として表示されています。
ここでもつい最近亡くなられた方の死因を誤って生成して断言していたことも見かけるなど、誤情報を平気で掲載することから人工無能といっても差し支えない一面も見せつけていますが、この記録ではこのサイトに関連した気になった点やAIなどの収集ボットに対する施策と、改めてCOTAのサイトの対外的な存在意義を強める方向性を模索する中での取り組みをご案内いたします。
経緯と考察を飛ばして、COTAのサイトでのAIに対する今後のご案内をご覧いただくには下部までスクロールをお願いいたします。
従来の検索であれば情報元へのリンクとして表示されていたので情報元となるサイトのクリエイターは文章等の創作物へたどりつく形でした。ところが一部の検索結果のページに生成AIによる要約が表示されるようになりました。
下記は「自分を大きく見せてしまう癖がある」というGoogle検索結果(2024年12月9日時点)です。情報は変動するため現在は変更されている場合があることをご容赦ください。
ここに検索結果よりも先にAIによって出力されているものが先に掲載されています。
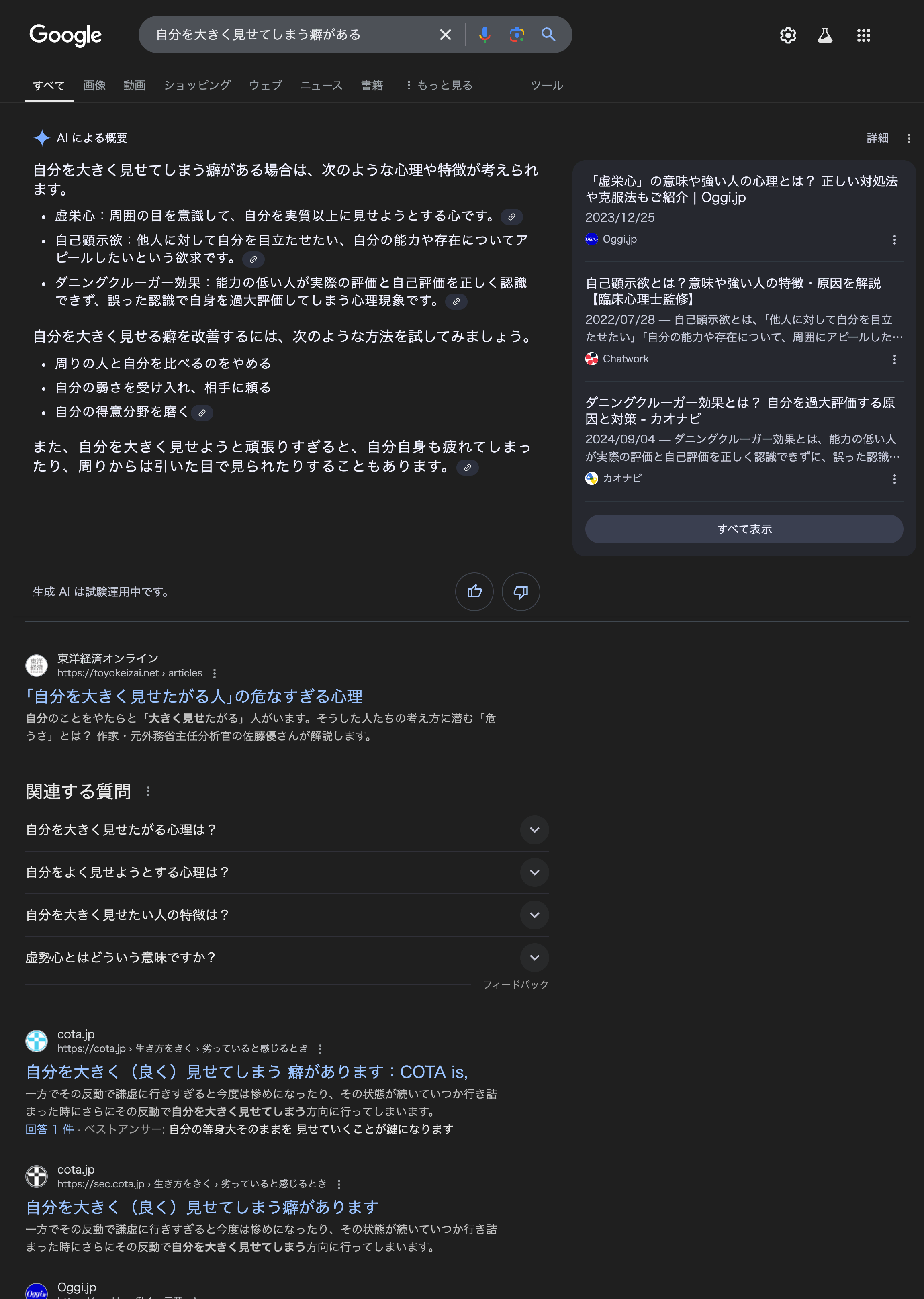
このAIの出力は要約とあるように他の情報元と混ざっています。掲載元のリンクも貼られていますが、しかしこの掲載元が必ずしも正しく掲載されているとも限らず、該当のページから類似した項目は見つけられませんでした。
下に従来の検索結果を辿ってみると、通常の検索結果としてCOTAのサイトの結果「自分を大きく(良く)見せてしまう 癖があります」が現れます。Google側としては認知していないと言うことは無理があります。サイト運営者からすれば、文章を他の文章と混ぜ合わせられた上に、正確な掲載元にも掲載されず辿りづけず、ただ頭を使って考えた文章だけがそのまま持っていかれてしまっている可能性があるわけです。
最初の文章は全く気にならなったのですが、最後の文章で取ってつけたように現れる項目に違和感があります。一見するとCOTAのサイトの単語と共通のものはないのですが、Googleが生成した文字「疲れてしまったり」は、COTAのサイト「反動で謙虚に行きすぎると今度は惨めになったり、その状態が続いていつか行き詰まった時にさらにその反動で自分を大きく見せてしまう」を短縮し変換したものと同一です。
またGoogleのAIの出力する「周りからは引いた目で見られたりする」は、COTAのサイトでいう「やがて人を寄せ付けなくなります」に対応します。
書いていて自分でもこじつけのように思えてきてしまいますが、単語として同一かどうかだけでは生成AIの出力物では分からない面があります。もちろんこれらはCOTAのサイトだけから持ってきていると断言できるものではありませんが、だからと言ってこの考えが多くの人が発想できるものだと飲み込むのも難しいところです。
これだけではなく他にも見ていくと色々と出てきます。

上のスクリーンショットは「タイパ コスパが悪い」という2024年11月25日現在のGoogleでの検索結果です。
「タイパが良いとコスパが悪い」をそのまま伝えているものはGoogleが提示する掲載元のリンクからは見つけられませんでした。
この言葉は私COTAが記事だけでなく繰り返しポッドキャストやライブ配信で話しているものです。もちろんこれも個別にここだけを切り取って問題とするならそれはこじつけにも思われて仕方がないのですが、こういう箇所が多すぎるわけです。
文章を書くことを生業としているライターであれば、文章の体裁だけではなくその奥にある発想の癖というのに敏感だと思います。この生成AIの文章の中にも、掲載元とされる言い回しこそ客観的かつ前後の文脈に合わせて整理されていますが、その中身には筆者の言い回しや着想の癖が垣間見れます。
当のGoogleが運営するYoutubeでも、作者が動画を投稿する際には生成AIを利用しているか否かの確認項目があるくらい、配信する側としてそのセンシティブな部分を強く認識させられるものです。
Youtubeではプレミアム会員など、作品そのものによって収益を明確に得ているから慎重なのでしょうか。

ところがそのデータを検索で利用する側となった途端に「試験運用中」の名の下に、あっけなく自分の手柄としてただの素材として曖昧に利用しているのは、さすがに印象がいいとは言えません。
これは自分だけでなく、COTAが他の人に対して願う「頑張っている人が報われてほしい」と望んでいる自分の考えにも反します。
昔「ブログ(ウェブログ)」というものが定着していった時代がありました。それ以前にもウェブ上で日記というものはありましたが、コメントなどのやり取りを行える場として広まったわけです。
その後、ブログが検索結果での順位を争うようになったり、商品紹介(PR)によるアフィリエイトというものが出てくると、創作能力に乏しい人々がネット上の他人の考えたものを織り交ぜて記事を作るようなことも出てきます。
今回取り上げているのはこれをボットが行なっているという違いにすぎないとも言えるわけです。しかし一次創作の能力が乏しい金欲しさのアフィリエイターであっても、そこには情報を自分の持っていきたい方向に配列するという思考と、何よりも感情があります。
生成AIの場合も一見すると、自分の持っていきたい方向に情報を収集し配列する点は変わらないでしょう。しかしビッグデータによって最適化された集合知が判断する最適な配列は、一種の一神教の宗教のようなものでもあります。
自分の言葉が特定の宗教の理念を表すものとして次々と収集されていくのを傍観するのは、創意工夫をする人ほど黙れと言われているような感覚に陥ります。特定の1人の人であれば訴訟を起こすことも含めて対抗しやすいものの、それが全人類となれば折れる他ないわけです。
「東京で大雨が発生した」という情報には著作権というものがなく(あると伝達に支障をきたす)、「私はこう思った」というものには著作権がある。著作権というのは「感情」とも言われます。
この感情を持っているかどうかは自分にとっては大切だと思っています。もう一つ、人間だからこその失敗や気づきの重要性の話もありますが、それはいずれお話ししていきます。
具体的には、このサイトを運営する対外的な意義も薄れてしまいます。そもそもソーシャルネットワークではなくお金をかけてでも独自のサイトを持つのは、著作を明確にして運営元に左右されることなく提供したいためです。
関係性を強者に委ねるべきものであるとして、対外的関係に文句があるなら全て閉鎖的な場所で日記として書いていればいいという方向もあるかもしれませんが、そうなってくるとインターネットそのものに疑問を投げかけていくことにつながります。やはり何かしらヒントになることがあるなら参考にしてもらえたらそれは嬉しいものです。もちろん参考にして欲しいのは欲深いボットではなく繊細な人間に、です。
検索結果に載せない方法はあります。しかしそれを行うとAIのみならず普通の検索結果に掲載されないことになります。個人のサイトが一切検索結果に乗らないというのは、ただでさえSNSと比べて繋がりが難しいだけに極端な対応でかなり難しいものです。
AI利用もこの扱いが気になるとはいえ、自分も使っているし今後の社会発展も考えれば拒絶しているわけでもありません。Googleのような扱い方は法令上は問題もないとされています。
Googleの検索結果も「生成 AI は試験運用中」とあるので、試験運用だからといって許されるものでも無いですが、今後の見せ方は変わっていく可能性はあります。
現状検索結果に掲載させない対応やクリエイティブ・コモンズライセンスがあります。
検索結果に掲載させない宣言には具体的に「noindex」という指定があります。このサイトを含め全てのウェブサイトではHTMLという記述がされていますが、この中で人の目では直視できない部分にこの記述をすることでボットに対して収集しないで欲しいと伝える手段です。
<meta name="robots" content="noindex" />上記の記述ではロボット(robots)に対して noindex (収集するな)と伝えています。これと同様に、
<meta name="ai-use-policy" content="noindex, noai">AI利用の信念(ai-use-policy)は収集されたくない(noindex)・使われたくない(no ai)といった宣言をする仕組みが検討されているようです。ただし2024年現在ではありませんし、これらはそのページ全体に対して行われるもので、部分的な拒否は行えません。
noindexはあくまでもシステムとしての都合・どちらかといえばボットの視点で作られたものであり、創作という人類が他の人間や道具(ボット)に対して行うにはクリエイティブ・コモンズライセンスのような宣言がよりわかりやすいだろうと思っています。
これはスタンスの違いでしかないです。ただし人類がボットのために存在しているのではない、という主従関係を明確にさせる意味で重要だと思っています
現状、クリエイティブ・コモンズを例として当然のように動画や写真は作品として取り扱われるのにも関わらず、キャッチコピーや文章は電子書籍を除いてHTMLとして出力されるこのようなサイトには作品性は問われないものとされている意識の点ですでに認識に問題が起きているように思うわけです。
ニュースのような情報伝達としての利用の側面も大きいことは理解しています。どちらに偏るのも問題だからこそ、HTML上で「著作物である」という宣言を人間として行う必要性を感じています。
COTAとしてはより踏み込んだものとして、生成AIの収集するボットに対してブロック(段落)ごとに下記のような階級別の宣言が行えるような仕組みができていくだろうと思います。
ただこれらも検索結果に掲載させないものが「宣言」にとどまるように、性善説の上でしか無いことも念頭におかないといけません。特に検索結果とは異なり、生成AIの場合は情報元となった文章を勝手に改変し、文脈に合わせてしまうために盗用をされても気づきづらい面があります。
野菜の苗からお店での販売までを追跡するトレーサビリティーと同様に、一定の文章に固有のIDを持たせる仕組みがない限りは難しいだろうと思うように、これらはWeb3の領域に関わってくるものだろうと思います。
生成AIに対する明確な主従環境を調教させるには、人間側の方がウェブ3以上のものへの移行が前提となってしまうことも想像できます。

しかし現状、このサイトに来ていただいているような方々に一気に移行を促すのは困難です。閲覧者にとってわかりやすい利益となる部分がありません。
ここからお話しすることは上記に書いた問題が解決するまでの中期的な対応です。自分から明確にできることとして、閲覧される方には一手間おかけしてしまうことになりますが、一部の核心となるコンテンツの一部分に閲覧制限を設けて認証を挟む形にしようと思います。
閲覧制限はログインすると解除されますが、ログイン・登録は基本的には何も記入しないでもアプリやSNSサイトにログインしていれば簡単に行えるものを設置しています。


2024年12月の段階では、Google、Discord、Facebook、Twitch、X、LINEに対応しています。本当はAppleも対応させたいのですが、法人確認と年額がかかるため断念しています。
今回のこの件のお話でメンバー会員を増やしたいという気持ちは無いので、人間が見るにあたって重要な部分については面倒なログイン制限は設けません。どちらかというとボットが重要としそうな箇所を中心に対して制限をします。
提供している文章の記録(記事)が、(1)相談の紹介→(2)ご相談内容→(3)簡単な回答→(4)具体的な例→(5)その他よくある例や補足→(6)それらを受けた結論 といった流れだとします。
その時にAIとしては(1)→(2)→(3)→(4)→(5)と流れがあって結論と全体の意味を把握するわけですが、人間の場合はある程度内容が欠落していても思考の流れを把握する能力があります(この人間の能力については今後お話しします)。AIはある箇所が欠落すると、起承転結で矛盾する無茶苦茶な文章を生成する傾向があります。
そこをうまく利用して、多くの人にとっては見なくても想像できなくはない部分や、キャッチーな部分を中心にログインを必要とさせることで、別にログインしなくてもわかるけれどAIなどボットには盗用を難しくさせるようにしていこうと思っています。
ログインを必要とするのは生成AIなどのボットに全ての情報収集を許可させないためであり、認証はあくまでもそのアカウントが存在することを目的としています。
ログインによって何ができるのかはログイン状況のページをご確認ください。
引用はもちろん盗用であっても自分の考えが活用されることはそれだけ価値が認められているということで喜ばしい面もあります。
閲覧に制限をかけることは、ユーザーの判別を個別にするためのデーターベースにも負荷がかかります。負荷をかけたくないためにコミュニティ機能は排除してきました。コストもかかります。それでもこのサイトがサイトとして、私COTAがCOTAとして生きている中で生んだものであるものを明確にさせ、意味を持たせるために行うことをお許しいただけたらと思います。
もちろん環境に左右されない・対外的ではない、自分の中でのサイトのあり方というのは核心であって今後も変えるつもりはありません。
これからも変わらず居ていただけたら幸いです。