
Dear not so cute AI – how to deal with COTA site

AI is no good because it is not cute. It does not make individualistic mistakes, if it fails, this time it does not admit it, but instead shrugs it off with dignity, it is ugly on all sides (hachi haibito) and puts on a good face to all kinds of people with “maybes” and the like, it has no convictions, it is immature but not pure, it has boiled human innards down to only the surface, it has knowledge but lives only on knowledge and is flimsy, it is not dependent on others As of 2024, he is a grotesque being who cannot exist without depending on others, and yet he has no core of his own while he pretends to be human.
While such artificial intelligence/generated AI is useful, it is often used for political purposes by generating videos based on real/existing persons against their will, by generating non-existent places of interest and putting them on tourist sites and closing them down, or by using illustrations generated by other illustrators without their permission for commercial purposes. The use of illustrations generated by other illustrators without permission for commercial purposes is often cited as a recent problem in 2024.
In this context, as of December 2024, the generated AI is also shown as a summary in the results of Google searches.
Here, too, we have seen that the cause of death of a person who recently passed away was incorrectly generated and affirmed, and the site also shows a side that can be said to be artificial incompetence, as it posts misinformation with impunity. We will guide you through our efforts as we seek a direction to strengthen the external significance of COTA’s site.
Please scroll down to the bottom to skip the background and discussion and see future guidance for AI on the COTA website.
Specific example: what I noticed about Google’s AI.
In conventional searches, the information was displayed as a link to the source of the information, so that the creators of the information source site could reach the text and other creative works. However, some search result pages now display summaries generated by AI.
Below are Google search results (as of December 9, 2024) for the phrase “I have a habit of making myself look big”. Please note that information is subject to change and may be current.
Here are the outputs by the AI prior to the search results, which are listed first.
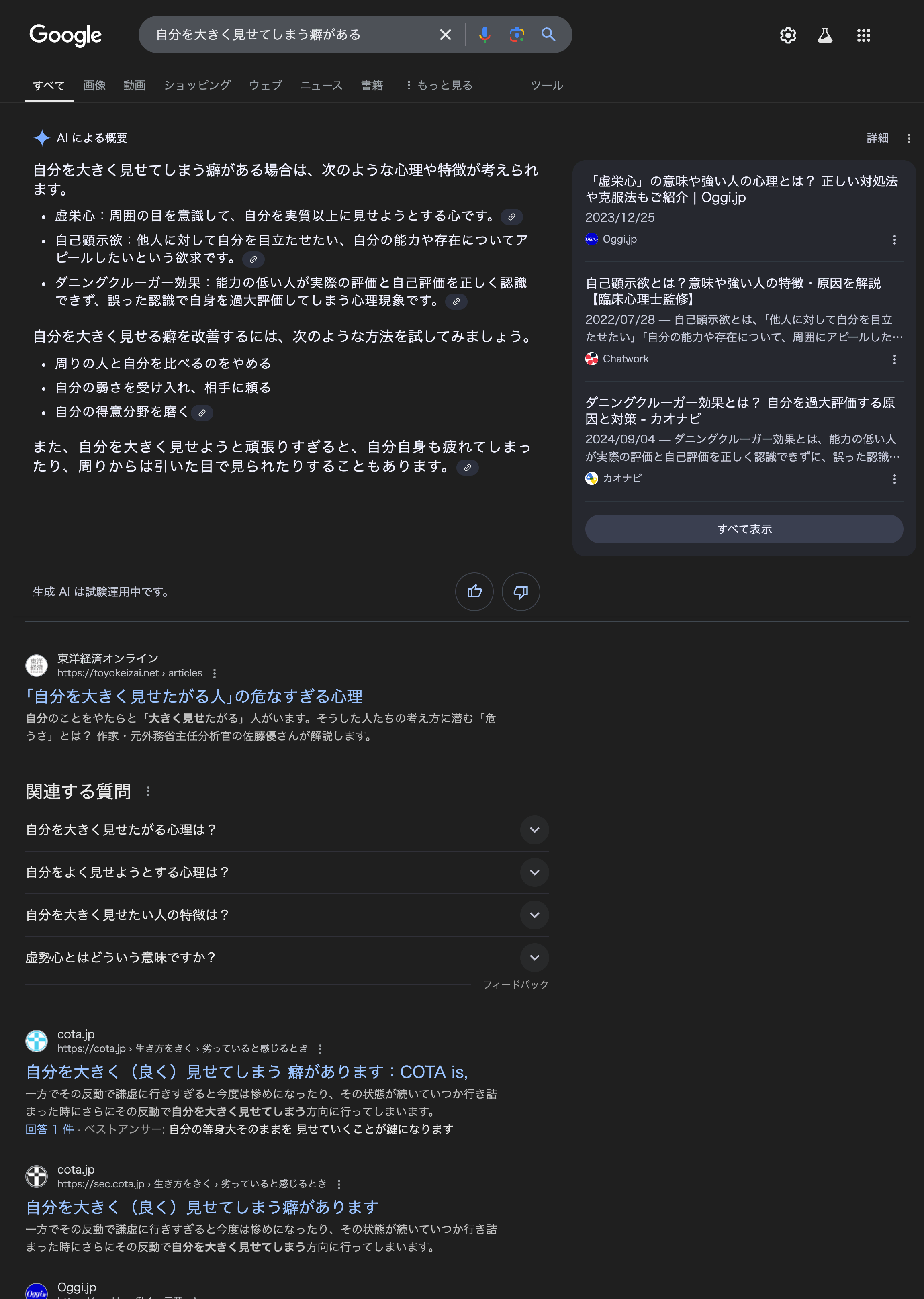
The output of this AI is mixed with other sources, as indicated by the summary. A link to the source is also provided, but this source is not always correct, and we could not find any similar entries on the relevant pages.
It is impossible to say that Google is not aware of this. For the site operator, it is possible that the text is mixed with other text and is not listed or traced back to the correct listing source, and only the text that was thought out with your brain is taken as it is.
Plagiarism, which is just rephrasing and rearranging words and expressions
The first sentence did not bother me at all, but I am uncomfortable with the item that appears in the last sentence as if it were an afterthought. At first glance, there is nothing in common with the words on the COTA site, but the Google-generated letters “tired or” are identical to the shortened version of the COTA site “If you go too humble in reaction, this time you will be miserable, and if that continues and you get stuck one day, the reaction will make you look even bigger”. The words are identical to the shortened and converted version of the COTA website.
Also, the output of Google’s AI, “people around you may look at you with a detached look,” corresponds to what the COTA site says, “Eventually, you will stop attracting people.
As I write this, it seems to me to be a bit of a stretch, but there are aspects of the output of the generated AI that cannot be determined just by whether or not they are identical as words. Of course, I can’t say for sure that these are brought from the COTA site alone, but that doesn’t make it any easier to swallow that this idea is something that many people can conceive.
This is not the only one, but there are many others to look at.

The screenshot above is a search result on Google as of November 25, 2024 for “Time Performance (TAIPA) and Cost Performance(COSPA)”.
Specific listing sources are prioritized for large companies and firms.
We were unable to find anything that directly conveys “Typa(Time Performance) is good for the costumers” from the links Google provided to the source of the listing.
These are words that I, COTA, have spoken repeatedly not only in articles but also in podcasts and live-streams. Of course, if I were to single out this particular part of the article as the problem, it would seem like a cop-out, but there are too many parts of the article that are like this.
Writers who write for a living are sensitive not only to the appearance of the text, but also to the habits of thought that lie behind the text. In this text by GenerateAI, the phrases that are considered to be the source of the text are objective and organized according to the context of the preceding and following sentences, but the contents of the text reveal the author’s phrasing and habits of inspiration.
Contradictory Google
Even Youtube, which is operated by Google, requires authors to confirm whether or not they are using AI when they post videos.
Is it prudent because Youtube clearly derives revenue from the work itself, such as premium memberships?

However, it is not a good impression to use the data ambiguously as mere material as one’s own credit under the name of “under test operation” as soon as one becomes the one to use the data in a search.
What’s wrong with that, unlike human modification?
This is contrary not only to myself, but also to my own idea of what COTA wishes for others, that they should be rewarded for their hard work.
Differences between blog aficionados and AI
There was a time when “blogs (weblogs)” took root. Although diaries had existed on the Web before then, they became popular as a place to exchange comments and other information.
Later, as blogs began to compete for rankings in search results and affiliate marketing through product placement (PR) emerged, people with limited creative skills began to weave together the ideas of others on the Internet to create articles.
The difference is that bots are doing this. But even money-hungry aficionados with little primary creative ability have the thought and, above all, the emotion to arrange information in the direction they want to take it.
At first glance, the case of generative AI will be no different in that it collects and arranges information in the direction it wants to take. However, the optimal sequence determined by the collective intelligence optimized by big data is also a kind of monotheistic religion.
To stand by and watch as one’s words are collected one after another as representing the ideals of a particular religion is like being told to shut up the more inventive you are. If it is one specific person, it is easy to counter, including filing a lawsuit, but if it is the entire human race, you have no choice but to fold.
Emotions accompany creative and copyrighted works.
There is no such thing as copyright in the information “heavy rain has occurred in Tokyo” (if there is, it would hinder communication), but there is copyright in “I thought this”. Copyright is also referred to as “emotion.
I believe it is important for me to have this emotion. There is another story about the importance of failure and awareness because we are human, which I will talk about in due course.
Reaffirming the significance of operating the site
Specifically, the external significance of operating this site will also diminish. The reason we have our own site in the first place, even if we have to spend money on it instead of a social network, is that we want to make our authorship clear and offer it without being dependent on the operator.
There may be a direction that if you have a complaint about external relations, you should just write everything as a diary in a closed place, assuming that the relationship should be left to the strong, but this would lead to questioning the Internet itself. If you can give us some hints, we would be happy if you could refer to them. Of course, I want to make this reference to sensitive people, not greedy bots.
What if I don’t put it in the search results?
There is a way to not be listed in the search results. However, if you do this, you will not be listed in the search results not only for AI but also for normal search results. It is very difficult for a personal site to not be listed in search results because it is more difficult to connect with a social networking site than with a social networking site.
Although I am concerned about this treatment of AI use as well, I am not rejecting it because I am also using it and considering future social development.
Maintenance of declarations for future generated AI
Google’s search results also say “Generate AI is under test operation,” so it is not permissible just because it is a test operation, but it is possible that the way it is shown in the future will change.
Currently, there are responses and Creative Commons licenses that do not allow them to be listed in search results.
The “noindex” is a specific way of declaring that a website should not be listed in search results. All websites, including this one, contain HTML, which is a way of telling bots that you do not want them to collect your site by placing this description in a part of the HTML that is not directly visible to the human eye.
<meta name="robots" content="noindex" />The above statement tells robots (robots) to noindex (do not collect). Similarly, the above statement tells robots (robots) noindex (don’t collect),
<meta name="ai-use-policy" content="noindex, noai">A mechanism for declaring AI use beliefs (ai-use-policy) such as do not want to be collected (noindex) or used (no ai) is being considered. However, this is not available as of 2024, and these are done for that entire page, not partial rejections.
We are not creating for bots, the need for a clear master-servant relationship.
The noindex was created for the convenience of the system and from the perspective of bots, and I believe that a declaration such as the Creative Commons license would be more understandable for human beings to do to other humans and tools (bots) in the creation process.
This is just a difference in stance. However, I think it is important to clarify the master-slave relationship that humanity does not exist for the sake of bots!
Currently, while videos and photos are treated as works of art as a matter of course, using Creative Commons as an example, I think there is already a problem in terms of awareness, where catch copy and text are considered to be unquestionable works of art for such sites that output them as HTML, with the exception of e-books. I think there is already a problem in terms of the awareness that the work quality is not questioned on such sites.
I understand that there is a large aspect of its use as a communication of information, such as news. It is a problem to be biased either way, which is why I feel the need to make a declaration as a human being that the work is a copyrighted work in HTML.
As a COTA, I believe that a more in-depth system will be developed that will allow the following class declarations to be made for each block (paragraph) for the bots that are collected by the generating AI.
- Permission is hereby granted to use this information in conjunction with other information in the generated material.”
- “Permission is hereby granted for generative use as stand-alone material.”
- Permission to reproduce.”
- I give you permission to post it with a link to the citation.”
- Such as, “We do not permit any use for AI.”
However, it must also be kept in mind that these are only on the basis of a good nature, as those that are not allowed to be listed in search results are only “declarations”. In particular, unlike search results, in the case of generated AI, it is difficult to recognize plagiarism because the original text is altered and contextualized on its own.
For example, what kind of structure is needed in the larger framework?
I think these would be things that would be involved in the realm of Web3, just as I think it would be difficult without a mechanism to have a unique ID for certain texts, similar to the traceability of vegetables from seedling to sale in the store.
One can imagine that to train a clear master-slave environment for a generative AI, the human side would have to move to a web3 or higher.

However, at present, it is difficult to encourage people like those who come to this site to make the transition all at once. There is no easy-to-understand benefit for visitors.
What to do at the COTA site
What I am going to discuss here is a medium-term response until the problems described above are resolved. As for what I can do to make it clear, I will put a restriction on viewing some of the core content and insert authentication, although it will be a hassle for those who view the site.
Viewing restrictions are lifted when you log in, but login/registration is basically set up to be easy if you are logged in to the application or social networking site without filling anything out.


As of December 2024, we support Google, Discord, Facebook, Twitch, X, and LINE. We would really like to support Apple as well, but have abandoned the idea due to the corporate verification and annual fee.
No restrictions in important areas
Since we are not interested in increasing the number of members in this case, we will not set troublesome login restrictions for the parts that are important for human viewers. Rather, we will restrict mainly the parts that bots may find important.
Suppose the text record (article) you are providing flows as follows: (1) introduction to the consultation, (2) description of the consultation, (3) brief response, (4) specific examples, (5) other common examples and supplements, and (6) conclusion following those examples and supplements.
AI does not have the ability to grasp the flow of thought if content is missing. Humans, however, are different. Even if a certain place is missing, we can recall it in our minds to some extent and supplement it.
I ma trying to take advantage of this and make it difficult for AI and other bots to steal the information by requiring a login, especially in areas that are catchy or not unimaginable to many people, although they can understand it without logging in.
The reason for requiring a login is to avoid allowing bots such as generative AI to collect all information, and authentication is only for the purpose of having the account in existence.
Please check the Login Status page to see what you can do with your login.
To strengthen the significance of the site.
In some respects, it is gratifying to know that one’s ideas are being utilized, even if they are plagiarized, not to mention quoted, because it means that their value is recognized.
Restricting browsing also places a burden on the database for individual user identification. We have eliminated community features because we do not want to overload the database. It is also costly. Nevertheless, I hope you will allow me to do this in order to make clear and meaningful what this site is as a site and what I, COTA, have generated in my life as COTA.
Of course, the idea of a site that is not influenced by the environment and is not external to it, is at the core of what I do, and I have no intention of changing it in the future.
We hope you will stay the same.













いたずらやボットによる悪用を防ぐため、コメントはSNSでログインの確認をした方かこのブログをフォロー(Fediverse)している方だけです