
尊敬的先生,否可愛的 AI – 在這個網站上可以做什麼

AI 沒用,因為它不可愛。 不要犯獨特的錯誤,如果你失敗了,這次不要承認並削減你的先令,以八方布蘇(八方美人)向所有人擺出“也許”這樣的好面孔,沒有信念,稚嫩但沒有純真,只在表面熬砸出人性污垢,有知識但只與知識一起生活,脆弱不堪。 它是一種怪誕的存在,不依靠人就無法存在,但具有人的面孔,沒有自我的核心。 截至 2024 年。
順便說一句,雖然這種人工智慧和生成式人工智慧很方便,但存在一個問題,即它被政治利用,根據真實的人和真實的人生成違背個人意願的視頻,並且不存在的景點被生成併發佈在旅遊景點上並關閉。 或者,未經其他插畫家作品許可生成的插圖的商業使用經常被認為是 2024 年和最近的一個問題。
同時,截至 2024 年 12 月,生成式 AI 在 Google 搜尋結果中顯示為摘要。
即使在這裡,我也看到最近去世的人的死因是錯誤生成和斷言的,可以肯定地說是人為的無能,因為它毫無問題地發佈了錯誤資訊,但在這份記錄中,我擔心與本網站相關的要點和針對人工智慧等收集機器人的措施。 我們想再次介紹我們為尋找加強 COTA 遺址外部存在意義的方向所做的努力。
跳過背景和討論,滾動到底部以查看 COTA 網站上有關 AI 的未來資訊。
具體示例:Google 的 AI 讓我感到困擾的地方
在傳統搜索的情況下,它顯示為指向資訊源的連結,因此作為資訊來源的網站的建立者以到達文本等創意作品的形式。 但是,某些搜尋結果頁面現在顯示生成式 AI 的摘要。
以下是 「我有讓自己看起來更大的習慣」 的谷歌搜尋結果(截至 2024 年 12 月 9 日)。 請注意,資訊可能會發生變化。
在這裡,AI 輸出的那些被發佈在搜尋結果之前。
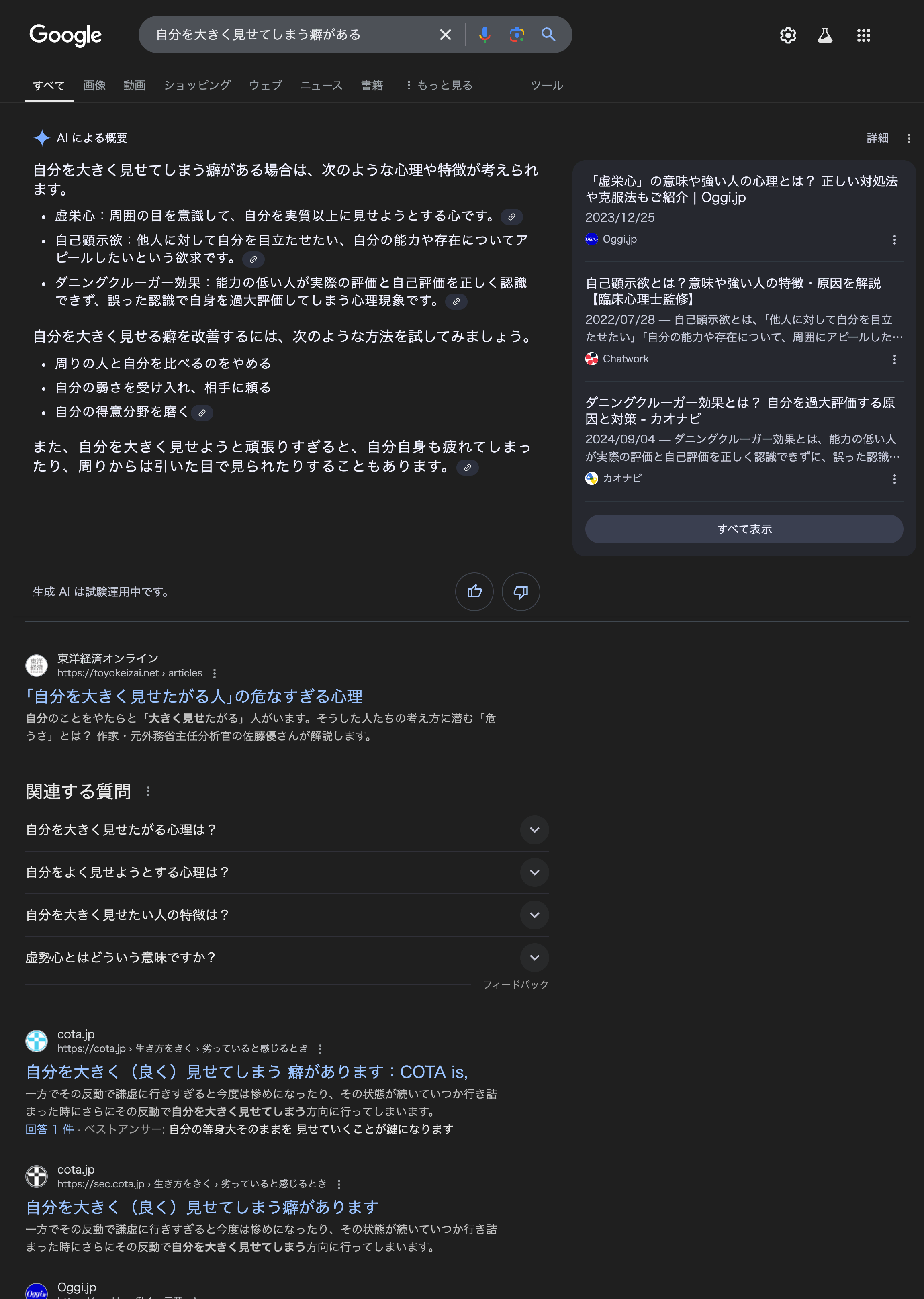
此 AI 的輸出與其他來源混合作為摘要。 還有一個指向來源的連結,但這個來源並不總是正確列出,我在頁面上找不到類似的專案。
如果您按照下面的常規搜尋結果進行操作,您將看到 COTA 網站的結果“我有一個讓自己看起來更大(更好)的習慣”作為普通搜尋結果。 說Google不知道這一點是沒有道理的。 從出版商的角度來看,有可能該文本與其他文本混合,並且沒有發佈在正確的來源,無法追蹤,只有那些想用他們大腦的句子才被原封不動地拿走。
剽竊只是對單詞和表達進行釋義和排序
第一句話根本沒有打擾我,但我對最後一句中出現的專案感到不舒服。 乍一看,與 COTA 網站上的文字沒有任何共同之處,但谷歌生成的“疲憊”字與 COTA 網站的縮短轉換版本相同“如果你在反應上太謙虛,你這次會很痛苦,如果你繼續處於那種狀態,總有一天會卡住,你會讓自己隨著反應而看起來更大”。
此外,谷歌的 AI 輸出「它會從你周圍的人那裡被拉扯的眼睛看到」對應於 COTA 網站上的“它最終會變得荒涼”。
當我寫它時,這對我來說似乎是一個技巧,但有些方面無法從生成式 AI 的輸出中僅通過它們是否與文字相同來理解。 當然,我們不能肯定地說這些只是從 COTA 網站帶來的,但這並不意味著很多人都可以構思這個想法是難以接受的。
不僅如此,當你看它們時,還會發現許多其他東西。

上面的截圖是截至 2024 年 11 月 25 日在 Google 上的搜尋結果,上面寫著 “氹仔性價比很差”。
具體來源由大公司和公司優先考慮。
我從Google提供的發佈來源的連結中找不到任何傳達「氹仔好,性價比差」的內容。
這是我 COTA 在我的文章以及我的播客和直播中反覆說過的話。 當然,如果你只單獨剪掉這部分並使其成為一個問題,那就無濟於事了,但像這樣的部分太多了。
如果你是一個以寫作為生的作家,我認為你不僅對句子的外觀很敏感,而且對它們背後的思想習慣也很敏感。 即使在這個生成式 AI 的文本中,據說是出版物來源的短語也是根據前後的上下文客觀組織的,但文本的內容讓人得以一窺作者的措辭和思想習慣。
自相矛盾的谷歌
即使在谷歌運營的 Youtube 上,當作者發佈視頻時,也會有一個確認項來查看是否使用了生成式 AI,因此它使發行商強烈意識到敏感部分。
您是否謹慎,因為Youtube顯然從工作本身(例如高級會員)中賺錢?

但是,一旦你成為使用數據進行搜索的人,你就以“試運行”的名義,隱約地把它當作自己的信用材料,這並不是一個好印象。
人工修改有什麼問題?
這不僅違背了我自己的信念,也違背了我自己的信念,即COTA希望他人的辛勤工作得到回報。
Blog Affiliate Marketer 和 AI 之間的區別
很久以前,“博客(weblogs)”開始建立。 在此之前,網路上有日記,但它作為一個可以交換評論的地方變得很普遍。
後來,當博客開始爭奪搜尋結果中的排名,通過產品介紹 (PR) 出現附屬公司時,創作能力差的人開始通過在互聯網上交織他人的想法來創作文章。
可以說,我們這次談論的只是機器人正在做這個的區別。 然而,即使你是一個貪財的聯盟行銷人員,初級創造能力很差,也有一個想法,最重要的是,有一種按照你想要的方向安排信息的感覺。
對於生成式 AI,乍一看,朝著你想要的方向收集和排列信息的觀點不會改變。 然而,用大數據優化的集體智慧來判斷的最優安排也是一種一神論宗教。
看著你的文字繼續被收集起來,作為特定宗教理想的表達,就像被告知要閉嘴,就像你有創造力一樣。 如果是一個特定的人,對抗它很容易,包括提起訴訟,但如果是全人類,別無選擇,只能打破。
創作和作品都伴隨著情感
“東京發生大雨”等信息沒有版權(如果有,會干擾通信),“我認為是這樣”有版權。 版權也被稱為“情感”。
我認為擁有這種感覺對我來說很重要。 還有一個故事是關於失敗和意識的重要性,因為我們是人,但我們將來會討論這一點。
重申運營網站的重要性
具體來說,運行此網站的外部意義也將降低。 首先,即使我們花錢而不是社交網路,我們之所以擁有自己的網站,是因為我們想澄清作者身份並在不受運營商影響的情況下提供它。
可能會有一個方向,如果有關於外部關係的投訴,應該把它寫成日記在一個封閉的地方,但這會導致對互聯網本身的質疑。 畢竟,如果有可以作為提示的東西,如果你能參考它,我會很高興。 當然,我希望你指的是敏感的人類,而不是貪婪的機器人。
我不應該被包含在搜尋結果中嗎?
有一些方法可以防止它出現在搜尋結果中。 但是,如果您這樣做,您將不會列在正常的搜尋結果中,而不僅僅是在 AI 中。 處理個人網站根本不出現在搜尋結果中的極端情況是相當困難的,因為它已經比SNS更難連接。
雖然我擔心人工智慧的使用,但我並不排斥它,因為我自己也在使用它並考慮社會的未來發展。 據說像谷歌一樣處理它的法律沒有問題。
為未來的生成式 AI 準備聲明
谷歌的搜尋結果還說“生成式 AI 正在試驗運行”,因此不能僅僅因為它是試驗就允許,但未來呈現的方式可能會發生變化。
目前,有一些措施不允許它在搜尋結果和 Creative Commons 許可證中列出。
不允許出現在搜尋結果中的聲明具有 「noindex」 的特定名稱。 所有網站,包括本站,都被描述為 HTML,但通過描述人眼無法直接看到的這部分網站,這是一種告訴機器人不要收集它的方法。
<meta name="robots" content="noindex" />在上面的描述中,我們告訴 robots 使用 noindex。 與此類似,
<meta name="ai-use-policy" content="noindex, noai">似乎正在考慮一種機制來聲明對使用 AI (ai-use-policy) 的信念不想被收集 (noindex) 或使用 (no ai)。 但是,截至 2024 年,這些是針對整個頁面的,而不是部分否認。
我們不是為機器人創造,我們需要明確的主從關係
Noindex 是從機器人的角度創建的,我認為像知識共用許可這樣的聲明對於人類來說更容易理解,以對抗其他人類和工具(機器人)。
這隻是立場上的差異。 然而,我認為這很重要,因為它澄清了人類對機器人來說不存在的主從關係
目前,儘管視頻和照片理所當然地被視為藝術作品,但以知識共用為例,我認為在意識到這些網站的作品不會受到質疑方面已經存在一個問題,其中流行語和句子被輸出為 HTML,電子書除外。
我知道它也被用作傳達資訊的一種方式,例如新聞。 因為對任何一個方向都有偏見都是有問題的,所以我覺得有必要作為人類在 HTML 上聲明“受版權保護的作品”。
作為對 COTA 的更深入的方法,我認為將創建一種機制,允許對生成式 AI 收集的機器人的每個塊(段落)進行以下排名聲明。
- “允許它與作為生成材料的其他資訊結合使用。”
- “允許作為單一材料生成和使用”
- “允許重新列印”
- “允許帶有引文來源鏈接的發佈”
- “我們不允許任何 AI 的使用”等。
但是,還必須記住,這些只是基於善的理論,就像不允許在搜尋結果中發佈的內容只是一個 「聲明」。 特別是,與搜尋結果不同,即使抄襲,生成式 AI 也很難被注意到,因為作為資訊來源的文本被任意更改並適應上下文。
例如,大型框架需要什麼樣的機制?
正如我認為除非有一種機制為某個句子提供唯一 ID,否則從蔬菜幼苗到商店銷售的可追溯性將很困難,我認為這些將與 Web3 領域有關。
我可以想像,為了為生成式 AI 訓練一個清晰的主從環境,人類方面將不得不轉向 Web3 以外的更多領域。

但是,目前很難鼓勵來到這個網站的人立即遷移。 沒有部分是觀眾容易理解的。
在 COTA 網站上做什麼
從這裡開始,我將討論的是中期應對,直到上述問題得到解決。 我可以明確的一件事是,對於查看它的人來說,這將花費大量的時間和精力,但我想對作為核心內容一部分的核心內容的一部分設置觀看限制,並以認證的形式進行干預。
登錄時會解除流覽限制,但如果您不填寫任何內容即可登錄應用程式或S月點,則登錄和註冊基本上很容易。


截至 2024 年 12 月,它與 Google、Discord、Facebook、Twitch、X 和 LINE 相容。 我也真的很想支援Apple,但我已經放棄了,因為這需要公司確認和年費。
我們不會在重要部分限制您
我不想在這個故事中增加會員人數,所以我不會為人類可以看到的重要部分設置麻煩的登錄限制。 相反,它將機器人限制在它可能重要的中心。
假設所提供的文本的記錄(文章)是 (1) 諮詢的介紹→(2) 諮詢的內容→ (3) 簡要回答→,(4) 具體示例→ (5) 其他常見示例和補充→以及 (6) 基於它們的結論。
那時,人工智慧有 (1) → (2) → (3) → (4) → (5) 的流程,掌握結論和整體意義,但在人類的情況下,即使內容有一定程度的缺失,它也有把握思想流動的能力(我以後會談到這種人類的能力)。 當 AI 缺少某個部分時,它往往會產生矛盾和荒謬的句子。
我將充分利用這一點,通過要求登錄以專注於許多人看不到而無法想像的部分,或者吸引人的部分,我認為我無需單獨登錄即可理解它們,但我將使 AI 等機器人難以抄襲。
之所以需要登錄,是為了防止生成式 AI 等機器人收集所有資訊,而身份驗證只是為了帳戶的存在。
請檢查登錄狀態頁面,瞭解登錄后可以做什麼。
加強網站的重要性
當然,即使是抄襲,也有一個令人高興的方面,這意味著你的想法被使用,因為它被認為是有價值的。
限制流覽還會給資料庫帶來壓力,使其難以區分使用者。 我們取消了 community 功能,因為我們不想給它帶來負擔。 這也是有代價的。 不過,我希望您能允許我作為一個網站來澄清和理解我在作為COTA的生活中作為COTA創建的內容。
當然,網站應該有的樣子,不受環境或外部的影響,才是網站的核心,以後我無意改變它。
我希望您將來能繼續留在我們身邊。













いたずらやボットによる悪用を防ぐため、コメントはSNSでログインの確認をした方かこのブログをフォロー(Fediverse)している方だけです